
服务热线
135-6963-3175
1、与redis集群设计思想对比
作为同是分布式架构的redis和es集群,两者的理念相同,都是为了解决高可用,提高容灾能力。但两者在具体设计方面还是有些许差异。
redis集群:数据存放在节点内的一组或多组槽(slot)中,节点本身分为主节点和备用节点,当某个主节点挂掉时,其备用节点可被提升为主节点。
es集群:节点有主节点(默认不存数据)和数据节点之分,数据存放在节点内的多个分片中,分片分为主分片和副本分片,同一主分片和它的副本分片存在于不同的节点内,当包含主分片的节点挂掉时,其位于其他节点内的某个副本分片会被提升为主分片。
主节点也就是 master 节点默认只负责维护 cluster state(这里记录了集群的一些元数据,比如节点的基本信息、index 设置、mapping 等等,可以通过 /_cluster/state 获取),数据节点也就是 data 节点才是存储数据的。
es master节点的职责:
1、由主节点负责ping 所有其他节点,判断是否有节点已经挂掉
2、创建或删除索引
3、决定分片在节点之间的分配
注意:虽然主节点也可以协调节点,路由搜索和从客户端新增数据到数据节点,但最好不要使用这些专用的主节点。一个重要的原则是,尽可能做尽量少的工作。推荐使用一个专门的主节点来控制集群,该节点将不处理任何用户请求。
2、shard&replica机制
1)每个index包含一个或多个shard;
2)每个shard都是一个最小工作单元,承载部分数据,lucene实例,完整的建立索引和处理请求的能力;
3)增减节点时,shard会自动在nodes中负载均衡;
4)primary shard和replica shard,每个document肯定只存在于某一个primary shard以及其对应的replica shard中,不可能存在于多个 primary shard;
5)replica shard是primary shard的副本,负责容错,以及承担读请求负载;
6)primary shard的数量在创建索引的时候就固定了(不可变),replica shard的数量可以随时修改;
7)primary shard的默认数量是1,replica默认是1,默认共有2个shard,1个primary shard,1个replica shard;
注意:es7以前primary shard的默认数量是5,replica默认是1,默认有10个shard,5个primary shard,5个replica shard;
8)primary shard不能和自己的replica shard放在同一个节点上(否则节点宕机,primary shard和副本都丢失,起不到容错的作用),但是.可以和其他primary shard的replica shard放在同一个节点上。
3、es集群数据同步机制
Elasticsearch采用一主多副复制方式,没有采用节点级别的主从复制,而是基于分片。
Index由多个Shard组成,每个Shard有一个主节点和多个副本节点。数据写入的时候,首先根据_routing规则对路由参数(路由参数默认使用_id,Index Request中可以设置使用哪个Filed的值作为路由参数)进行Hash确定要写入的Shard,最后从集群的Meta中找出该Shard的Primary节点写入数据,Primary Shard成功写入数据后,Primary Shard将请求同时发送给多个Replica Shard(InSyncAllocationIds),请求在全部Replica Shard上执行成功并响应Primary Shard后,Primary Shard返回结果给客户端。
该模式,Primary要等所有Replica返回才能返回给客户端,那么延迟就会受到最慢的Replica的影响,写入操作的延时就等于latency = Latency(Primary Write) + Max(Replicas Write)。副本的存在,降低了写入效率会较低,但是可以避免单机或磁盘故障导致数据丢失。
Replica写入失败,Primary会执行一些重试逻辑,尽可能保障Replica中写入成功。如果一个Replica最终写入失败,Primary会将Replica节点报告给Master,然后Master更新Meta中Index的InSyncAllocations配置,将Replica从中移除,移除后它就不再承担读请求。在Meta更新到各个Node之前,用户可能还会读到这个Replica的数据,但是更新了Meta之后就不会了。所以这个方案并不是非常的严格,考虑到ES本身就是一个近实时系统,数据写入后需要refresh才可见,所以一般情况下,在短期内读到旧数据应该也是可接受的。
设置wait_for_active_shards参数(可在Index的setting、请求中设置)可保证Es集群数据一致性更高的可能性。该参数设置每次写入shard至少具有的active副本数,如果副本数小于参数值,此时不允许写入。
4、ElasticSearch节点数据写入机制
由于Lucene的索引读写的隔离性,需要在添文档后对IndexWriter进行commit,在搜索的时候IndexReader需要重新的打开,这样才能保证查询结果的实时性,然而当硬盘上的索引非常大的时候,IndexWriter的commit操作和IndexReader的open操作都是非常慢的,根本达不到实时性的需要。ElasticSearch是如何解决可见性问题呢?
流程:
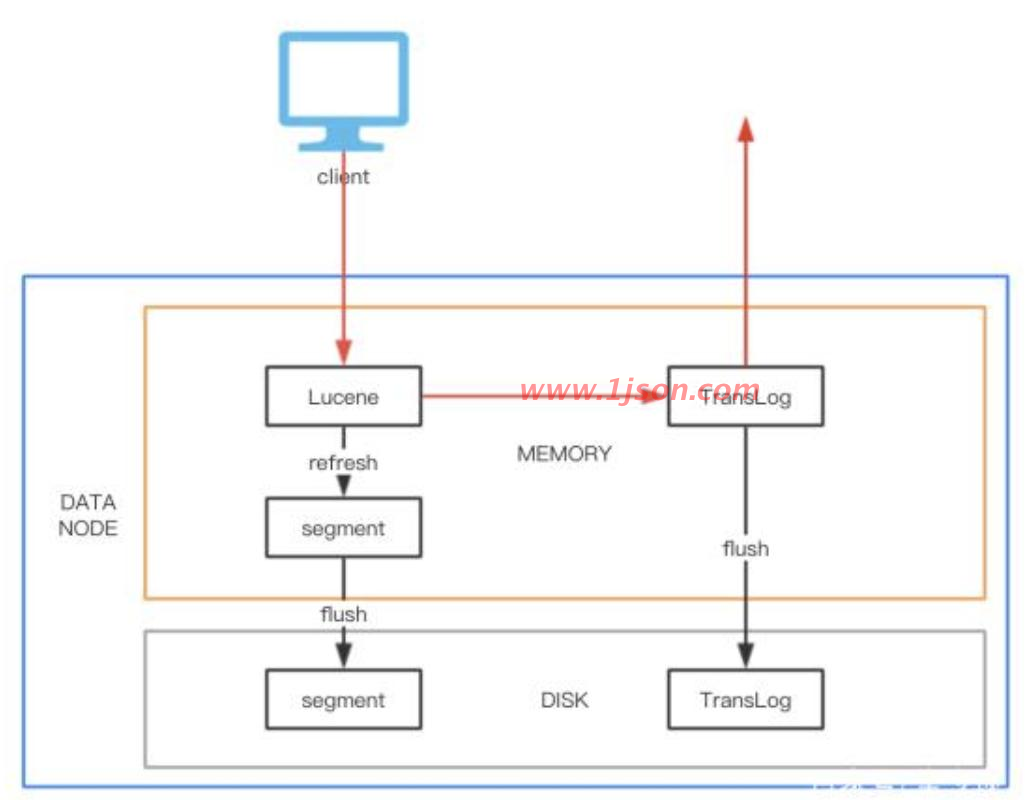
如上图所示,
1、请求到达DataNode后,首先经过Lucene引擎生成document存入到indexing buffer区中;
2、然后通过refresh操作(默认情况下,es集群中的每个shard会每隔1秒自动refresh一次,这是es是近实时的搜索引擎而不是实时的原因)将indexing buffer区中新增Document在filesystem cache中生成segment,这个sengment就可以打开和查询,从而确保在可见性,refresh操作是非常轻量级的,相对耗时较少;
3、之后经过一定的间隔或外部触发后segment才会被flush到磁盘上,这个操作非常耗时。flush操作完成后会清空掉旧的TransLog。
为了避免segement从内存flush到磁盘这段时间节点crash掉,导致数据丢失,数据经过lucene引擎处理后会写入TransLog,当节点重 启后会根据TransLog恢复数据到Checkpoint。通过设置TransLog的Flush频率可以控制可靠性,要么是按请求,每次请求都Flush;要 么是按时间,每隔一段时间Flush一次。一般为了性能考虑,会设置为每隔5秒或者1分钟Flush一次,Flush间隔时间越长,可靠性就会越 低。对于GetById查询,可以直接从TransLog中获取数据,这时候就成了RT(Real Time)实时系统。
5、数据一致性保障
1)持久性:通过Replica和TransLog两种机制来共同保障。
2)一致性:数据写入成功后,需完成refresh操作之后才可读,由于无法保证Primary和Replica可同时refresh,所以会出现查询不稳定的情 况,这里只能实现最终一致性。
ES 数据并发冲突控制是基于的乐观锁和版本号的机制:
一个document第一次创建的时候,它的_version内部版本号就是1;以后,每次对这个document执行修改或者删除操作,都会对这个_version版本号自动加1;哪怕是删除,也会对这条数据的版本号加1(假删除)。
客户端对es数据做更新的时候,如果带上了版本号,那带的版本号与es中文档的版本号一致才能修改成功,否则抛出异常。如果客户端没有带上版本号,首先会读取最新版本号才做更新尝试,这个尝试类似于CAS操作,可能需要尝试很多次才能成功。乐观锁的好处是不需要互斥锁的参与。
es节点更新之后会向副本节点同步更新数据(同步写入),直到所有副本都更新了才返回成功。
3)原子性:Add和Delete直接调用Lucene的接口,进行原子操作。update操作通过Delete-Then-Add完成,在Delete操作之前会加Refresh Lock,禁止Refresh操作,等Add操作完成后释放Refresh Lock后才能被Refresh,这样就保证了Delete-Then-Add的原子性。
4)隔离性:采用Version和局部锁来保证更新的是特定版本的数据。
要保证数据写入到ElasticSerach是安全的,高可靠的,需要如下的配置:
设置wait_for_active_shards参数大于等于2。
设置TransLog的Flush策略为每个请求都要Flush。
6、节点宕机,replica容错,数据恢复
master宕机:会重新选举新的 master,集群为red;
replica容错:新master将replica提升为primary shard,yellow;
非master宕机:该节点上primary shard对应的在其他节点上的某个replica shard升级为primary shard, 宕机恢复后, 该宕机节点上的 primary shard 转为 replica shard。
重启宕机node:master copy replica到该node,使用原有的shard并同步宕机后的修改,green。
7、ES副本同步是在refresh之前还是之后?
副本同步跟refresh没关系,refresh是针对shard,主备shard的refresh都是独立的。
数据refresh之前会被分发,然后各自独立refresh,一般这个时间都是不一样的。
8、增减或减少节点时的数据rebalance
新增或减少es实例时,es集群会将数据重新分配。
9、单node环境下创建index是什么样子的
1)单node环境下,创建一个index,有3个primary shard,3个replica shard;
2)集群status是yellow;
3)这个时候,只会将3个primary shard分配到仅有的一个node上去,另外3个replica shard是无法分配的;
4)集群可以正常工作,但是一旦出现节点宕机,数据全部丢失,而且集群不可用,无法承接任何请求。
PUT /test_index1{ "settings" : { "number_of_shards" : 3, "number_of_replicas" : 1 }}10、横向扩容
1)分片自动负载均衡,分片向空闲机器转移。
2)每个节点存储更少分片,系统资源给与每个分片的资源更多,整体集群性能提高。
3)扩容极限:节点数大于整体分片数,则必有空闲机器。
4)超出扩容极限时,可以增加副本数,如设置副本数为2,总共3*3=9个分片。9台机器同时运行,存储和搜索性能更强。容错性更好。
5)容错性:只要一个索引的所有主分片在,集群就就可以运行。
11、文档存储路由算法机制
哈希值对主分片数取模。shard = hash(routing) % number_of_primary_shards。
对一个文档经行crud时,都会带一个路由值 routing number。默认为文档_id(可能是手动指定,也可能是自动生成)。
手动指定routing number:
PUT /test_index/_doc/15?routing=num{ "num": 0, "tags": []}场景:在程序中,架构师可以手动指定已有数据的一个属性为路由值,好处是可以定制一类文档数据存储到一个分片中。缺点是设计不好,会造成数据倾斜。所以,不同文档尽量放到不同的索引中。剩下的事情交给es集群自己处理。
12、主分片数量不可变
涉及到以往数据的查询搜索,所以一旦建立索引,主分片数不可变。
13、增删改内部机制
1)客户端选择一个node发送请求过去,这个node就是coordinating node(协调节点)
2)coordinating node,对document进行路由,将请求转发给对应的node(有primary shard)
3)实际的node上的primary shard处理请求,然后将数据同步到replica node。
4)coordinating node,如果发现primary node和所有replica node都搞定之后,就返回响应结果给客户端。
14、文档的查询内部机制
1)客户端发送请求到任意一个node,成为coordinate node;
2)coordinate node对document进行路由,将请求转发到对应的node,此时会使用round-robin随机轮询算法,在primary shard以及其所有replica中随机选择一个,让读请求负载均衡;
3)接收请求的node返回document给coordinate node;
4)coordinate node返回document给客户端
5)特殊情况:document如果还在建立索引过程中,可能只有primary shard有,任何一个replica shard都没有,此时可能会导致无法读取到document,但是document完成索引建立之后,primary shard和replica shard就都有了。
15、es之集群角色类型
主节点
主节点的主要职责是负责集群层面的相关操作,管理集群变更,如创建或删除索引,跟踪哪些节点是群集的一部分,并决定哪些分片分配给相关的节点。
主节点也可以作为数据节点,但稳定的主节点对集群的健康是非常重要的,默认情况下任何一个集群中的节点都有可能被选为主节点,索引数据和搜索查询等操作会占用大量的cpu,内存,io资源,为了确保一个集群的稳定,分离主节点和数据节点是一个比较好的选择。
node.master:true node.data:false
候选主节点(Master-eligible)
候选主节点不仅有选举权还有被选举权,该节点拥有master 角色,能够在集群故障时被选举为master node。
数据节点
数据节点主要是存储索引数据的节点,执行数据相关操作:CRUD、搜索,聚合操作等。数据节点对cpu,内存,I/O要求较高, 在优化的时候需要监控数据节点的状态,当资源不够的时候,需要在集群中添加新的节点。
通过配置node.data:true(默认来是一个节点成为数据节点),也可以通过下面配置创建一个数据节点:
node.master:false node.data:true node.ingest:false
预处理节点
这是从5.0版本开始引入的概念。预处理操作运行在索引文档之前,即写入数据之前,通过事先定义好的一系列processors(处理器)和pipeline(管道),对数据进行某种转换、富化。processors和pipeline拦截bulk和index请求,在应用相关操作后将文档传回给index或bulk API。
默认情况下,在所有的节点启用ingest。如果想在某个节点上禁用ingest,则可以田间配置node.ingest:false,也可以通过下面的配置创建一个仅用于预处理的节点:
node.master:false node.data:false node.ingest:true
协调节点(Coordinating node)
客户端请求可以发送到集群的任何节点,每个节点都知道任意文档所处的位置,然后转发这些请求,收集数据并返回给客户端,处理客户端请求的节点称为协调节点。
协调节点将请求转发给保存数据的数据节点。每个数据节点在本地执行请求,并将结果返回给协调节点。协调节点收集完数据合,将每个数据节点的结果合并为单个全局结果。对结果收集和排序的过程可能需要很多CPU和内存资源。
通过下面配置创建一个仅用于协调的节点:
node.master:false node.data:false node.ingest:false
在ES5.0之前还有一个客户端节点(Node client)的角色,它不做主节点,也不做数据节点,仅用于路由请求,本质上是一个智能负载均衡器(从负载其的定义来说,只能和非只能的区别在于是否知道访问的内容存在于哪个节点),从5.0版本开始,这个角色被协调节点(Coordinating only node)取代。
部落节点
tribes(部落)功能允许部落节点在多个集群之间充当联合客户端。
部落节点是一个单独的节点,其主要工作是嗅探远程集群的集群状态,并将它们合并在一起。为了做到这一点,它加入了所有的远程集群,使它成为一个非特殊的节点,它不属于自己的集群,而是加入了多个集群。
也被称为跨集群搜索的功能,该功能允许用户不仅跨本地索引,而且跨群集撰写搜索。这意味着可以搜索属于其他远程群集的数据。
16、分片建议
。。。。
待总结...
